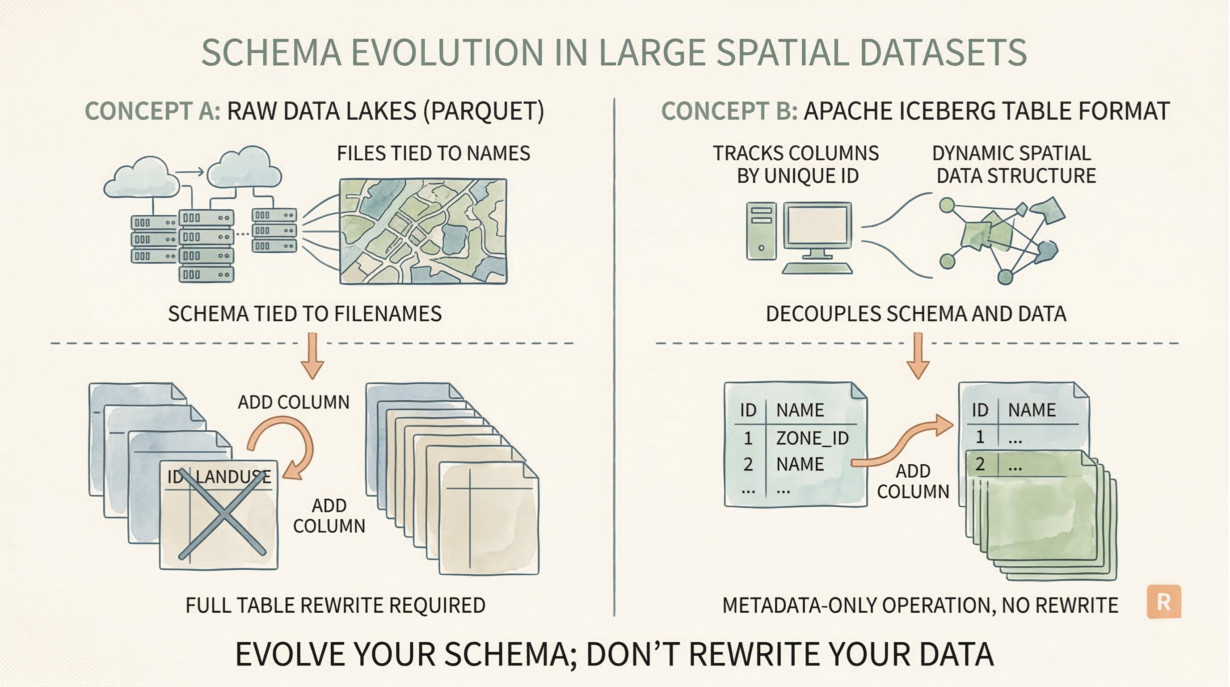
Most data lakes require full table rewrites for schema changes. Add a risk score to a billion-row spatial dataset? Rewrite all files. Rename a legacy attribute? Rewrite all files. This is why traditional databases and raw Parquet lakes grind to a halt when schemas evolve.
Iceberg decouples schema from data by tracking columns by unique ID, not name. Add a column: pure metadata operation. The underlying files don’t change. The table grows instantly. No compute, no rewrite.
Why this matters for spatial data: Spatial datasets are massive and schema changes are constant. Classification systems get updated. New attributes get added (risk scores, climate projections). Legacy GIS systems have terrible naming. A production zoning layer with 500GB of history can’t afford a full rewrite every time you refine a model.
Iceberg’s ID-based tracking makes this safe. Rename owner_name to property_owner in the schema. The underlying Parquet files still call it owner_name. Iceberg’s metadata maps the ID to both names seamlessly. No data moved. No downstream pipeline breaks.
Dropping columns is equally instant. Remove an obsolete field from the schema metadata. The files retain the bytes (wasted space—minimal). New readers ignore them. Old readers still work because IDs don’t change.
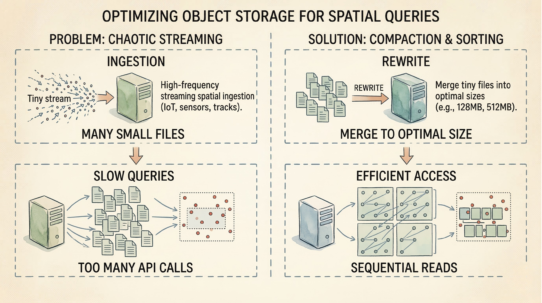
Raw Parquet data lakes can’t do this. Schema drift across partitions creates NullPointerException errors. Renaming requires ETL. Adding columns means rewriting files that already exist.
The rule: Evolve your schema; don’t rewrite your data. Track attributes by ID, not legacy names. If adding a field requires massive compute, you need a table format.