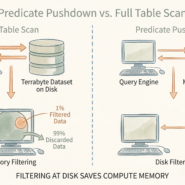
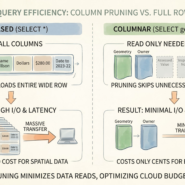
Your GeoParquet performance is fixed the moment you write the file. It’s determined by how you structure row groups and whether data is spatially sorted. The query engine can’t save bad data layout.
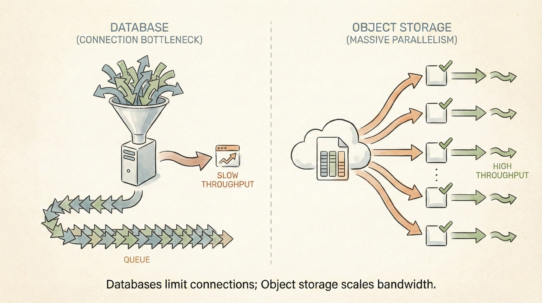
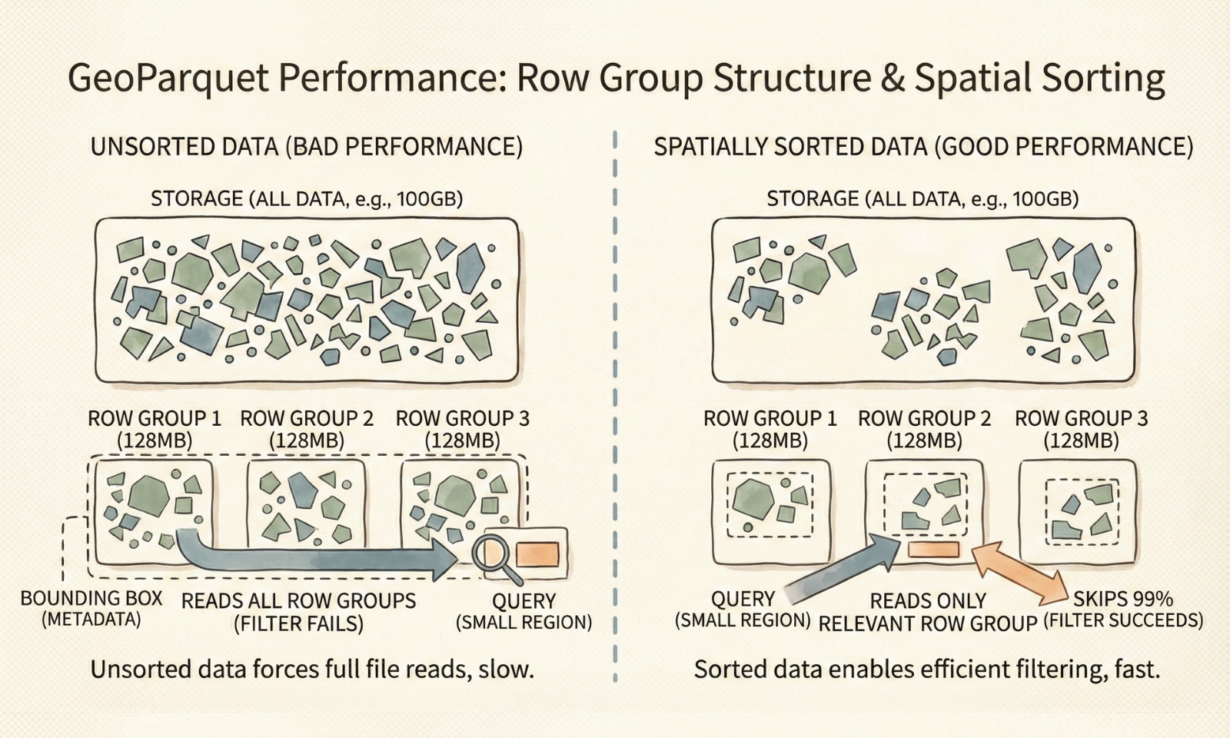
A row group is a horizontal partition within a Parquet file—a chunk containing complete rows across all columns (geometry, attributes, everything). Parquet breaks files into row groups because engines read entire groups at once. If you need 10 rows in a 128MB row group, you read all 128MB. That’s the unit of access.
For spatial data, row groups only become efficient if they’re spatially clustered. Store rows randomly? Every row group’s bounding box spans the entire extent. A query for “features in this small region” must read every row group. Store rows by spatial location (Hilbert curve, Z-order)? Each row group has a tight geographic footprint. A query checks metadata bounds, skips 99% of row groups, reads only the relevant ones.
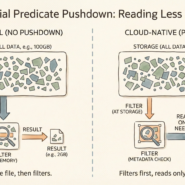
This “zone map” filtering is the physical mechanism enabling predicate pushdown. Metadata stores min/max coordinates for each row group. Queries check these bounds instantly, decide whether to read or skip.
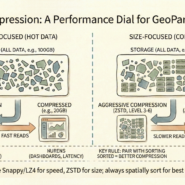
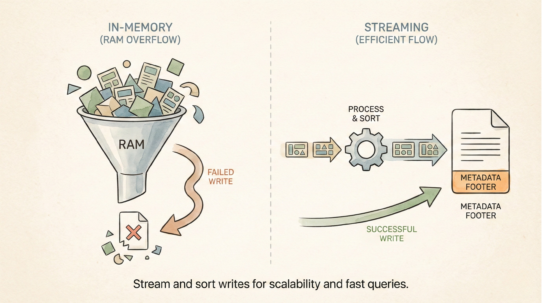
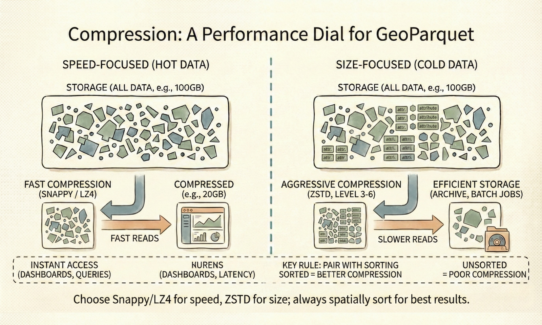
Row group sizing matters. Too small (10MB) creates metadata overhead. Too large (1GB) forces reading unnecessary data. For cloud-native workloads, 100MB-500MB is typical. The absolute requirement: spatial sorting before writing. Tools like GDAL, GeoPandas, and Apache Sedona handle this, but only if configured correctly.
The rule: Sort data by space before writing. Chunk by size. Unsorted GeoParquet performs worse than GeoJSON. Structure determines efficiency, not the query.