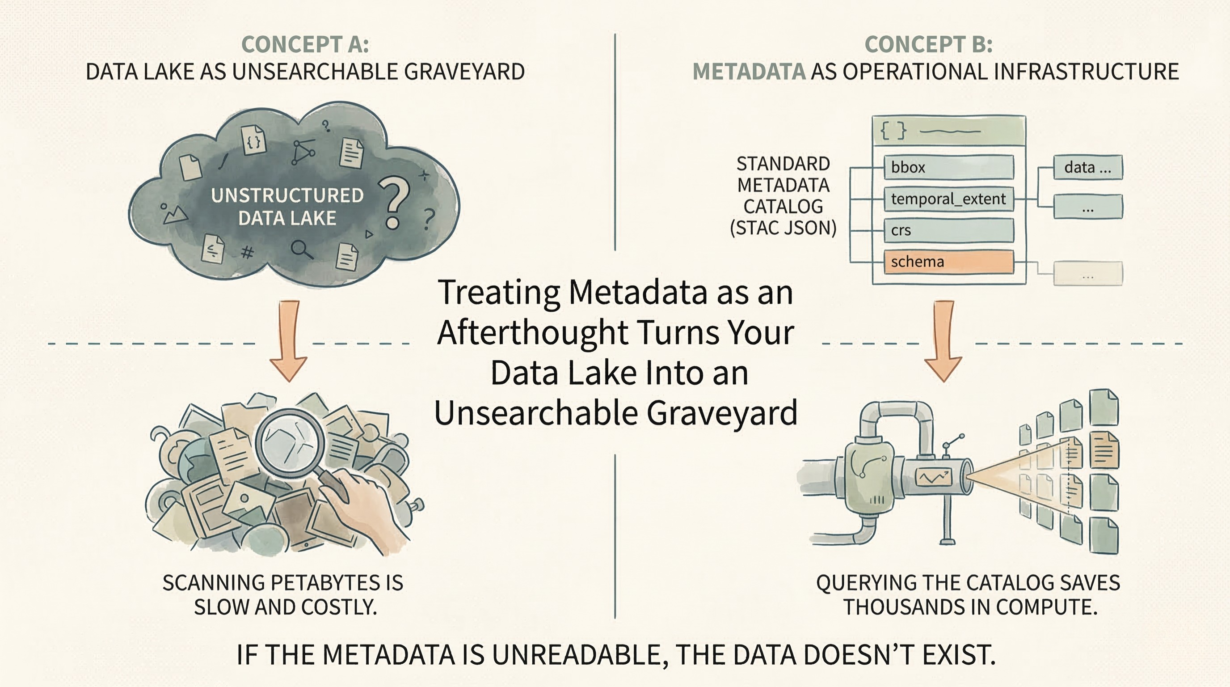
Metadata is not documentation. It’s operational infrastructure. A dataset without machine-readable metadata is a black box that causes silent pipeline failures and wastes compute on discovery.
Metadata is an active index. A bounding box in metadata lets systems skip entire regions without reading the data. A temporal extent answers “does this dataset cover 2023?” instantly, without scanning files. A standardized CRS field prevents silent projection errors. This is not metadata for humans—it’s metadata for pipelines.
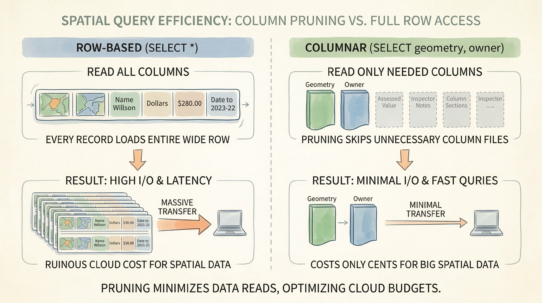
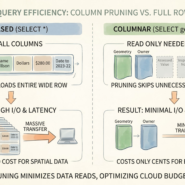
Query the catalog before you read the data. “Find all satellite imagery in this region, captured in 2024, with less than 10% cloud cover.” A catalog like STAC (SpatioTemporal Asset Catalog) answers this with JSON metadata, not by scanning petabytes of raster files. The query costs milliseconds. Skipping unnecessary data saves thousands of dollars in compute.
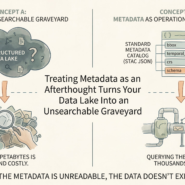
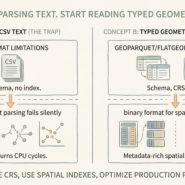
Machine-readable metadata is non-negotiable. Metadata buried in unstructured PDFs is useless to automated systems. “The CRS is described in section 3.2” destroys pipeline automation. Use standardized fields: crs, bbox, temporal_extent, schema. Enforce strict validation. If metadata is missing, the data doesn’t exist—reject the ingestion.
Enforce metadata generation at the point of ingestion, not as an afterthought. A pipeline that generates Parquet files should simultaneously produce metadata. Make it atomic. No data without context.
Standardized catalogs enable discovery across organizational silos. Different teams, different systems, one searchable API.
The rule: Query the metadata before you pay to read the data. If your pipeline can’t parse the metadata, the data doesn’t exist. A spatial dataset without a machine-readable CRS is an operational liability, not an asset.