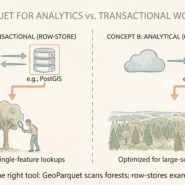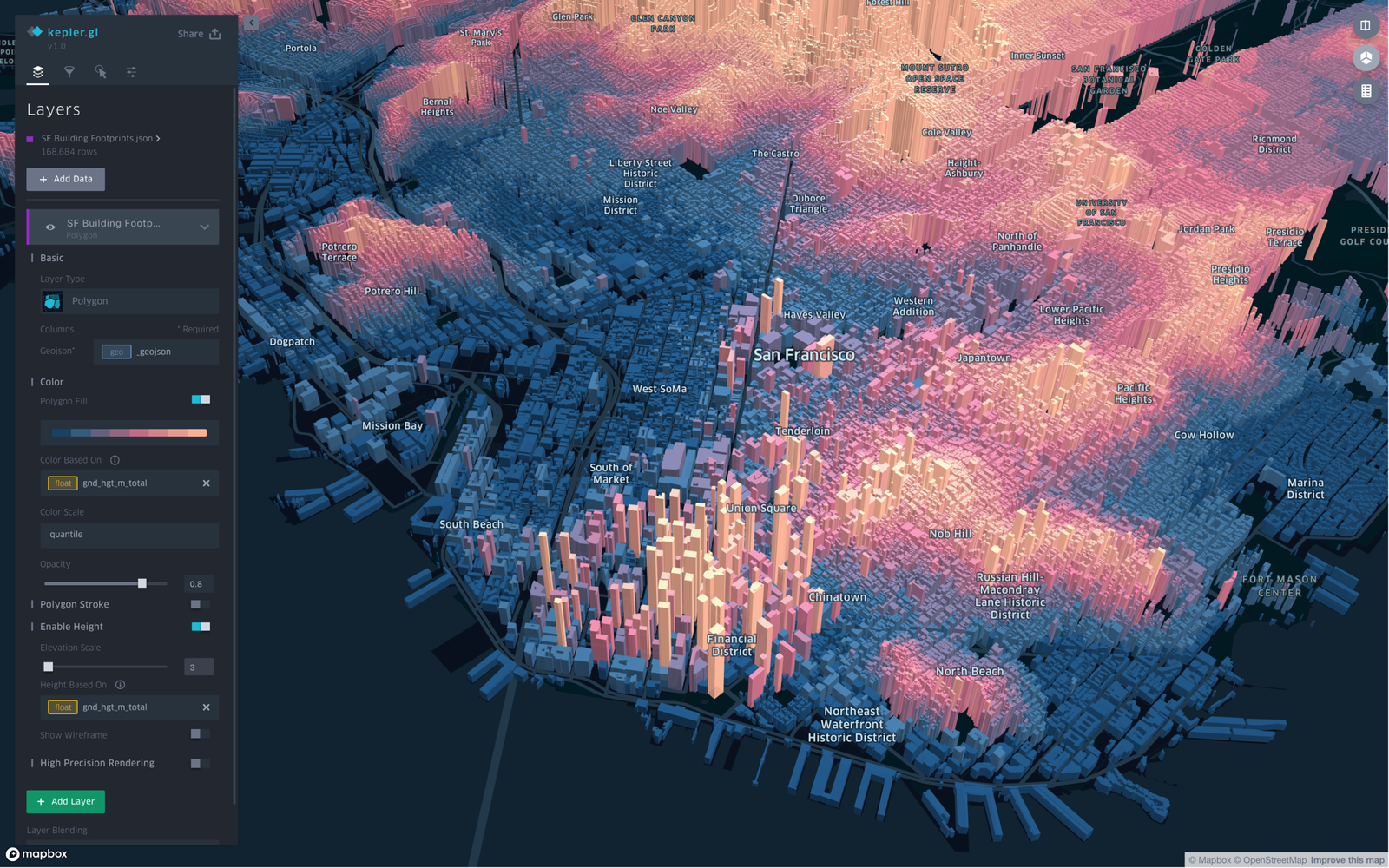
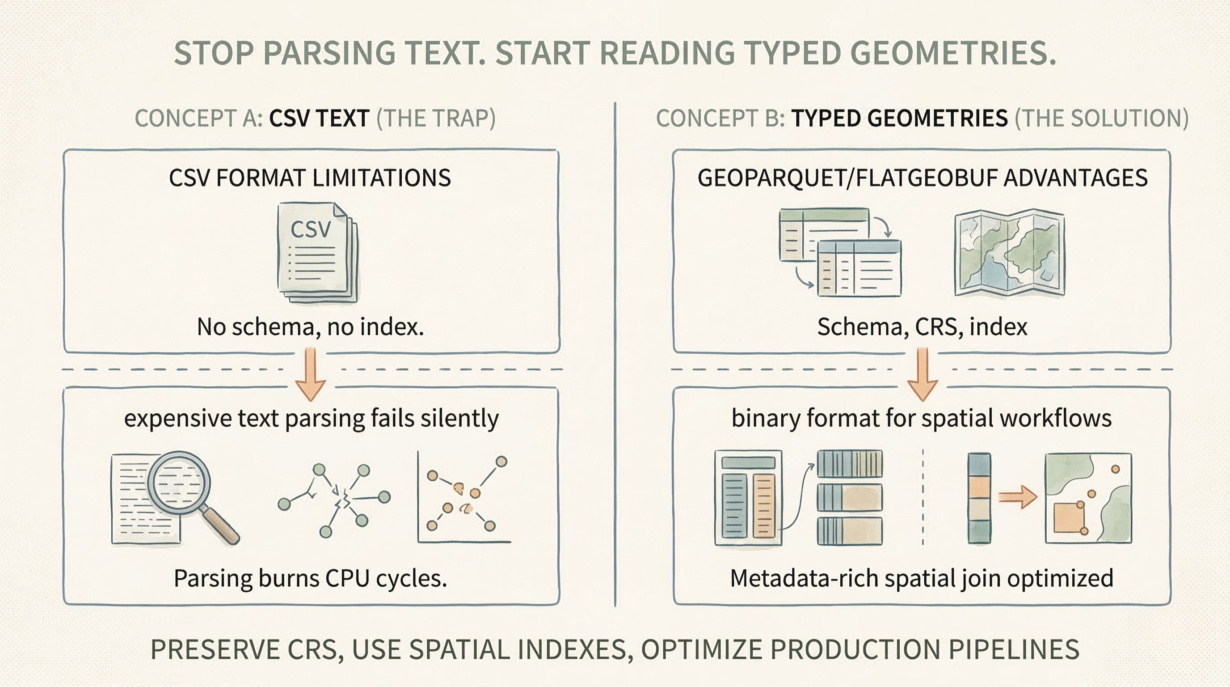
CSV files are a trap for spatial workflows. No CRS. No schema enforcement. No spatial indexes. Every read forces expensive text parsing that fails silently.
A CSV has no concept of a Coordinate Reference System. You export latitude and longitude as columns, losing the CRS entirely. The downstream pipeline guesses: “probably EPSG:4326?” If it guesses wrong, every distance calculation is wrong. Every buffer is wrong. The errors compound invisibly.
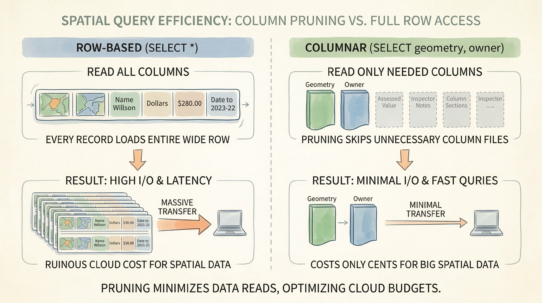
Text parsing is brutally expensive. A CSV coordinate is a string: "-122.456789". Reading it requires parsing text to float, then reconstructing geometry from Well-Known Text. A binary format like GeoParquet stores coordinates as IEEE 754 doubles—just copy them into memory. CSV parsing burns CPU cycles on every read. At scale, this cost explodes.
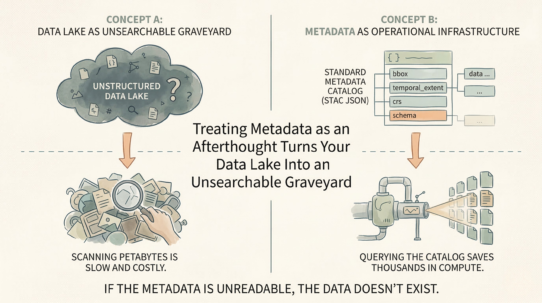
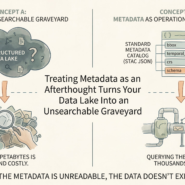
Schema enforcement is missing. A CSV has no metadata about what columns mean. Is longitude really longitude, or is it stored in the opposite order? Are missing values NULL or just blank? Downstream systems guess. Silent truncation happens. Features vanish.
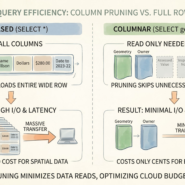
Spatial queries require full scans. A CSV has no bounding box metadata, no spatial index. “Find features in this region” reads every row. No predicate pushdown. No optimization. A modern format stores min/max bounds and enables the database to skip 99% of the data.
Use CSV only for simple one-off exchanges of point data with non-technical users. For production pipelines, use GeoParquet or FlatGeobuf. Schema-enforced. CRS-preserved. Indexed. Metadata-rich.
The rule: If your pipeline guesses the CRS from a column header, your architecture is fragile. Reconstructing WKT from CSV wastes more compute than the actual spatial join.