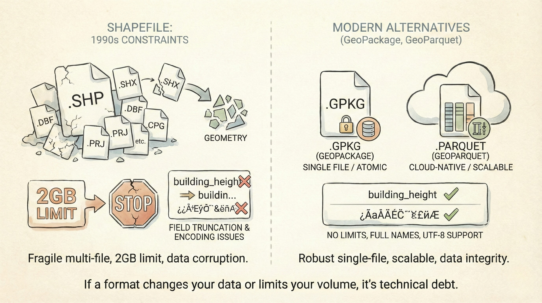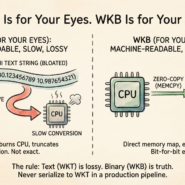
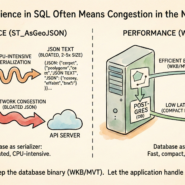
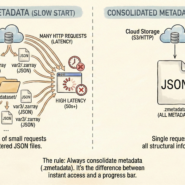
A PostGIS database can handle maybe 100 concurrent connections before performance degrades. A Parquet file on S3 can feed 10,000 parallel queries without breaking a sweat. The difference is architecture.
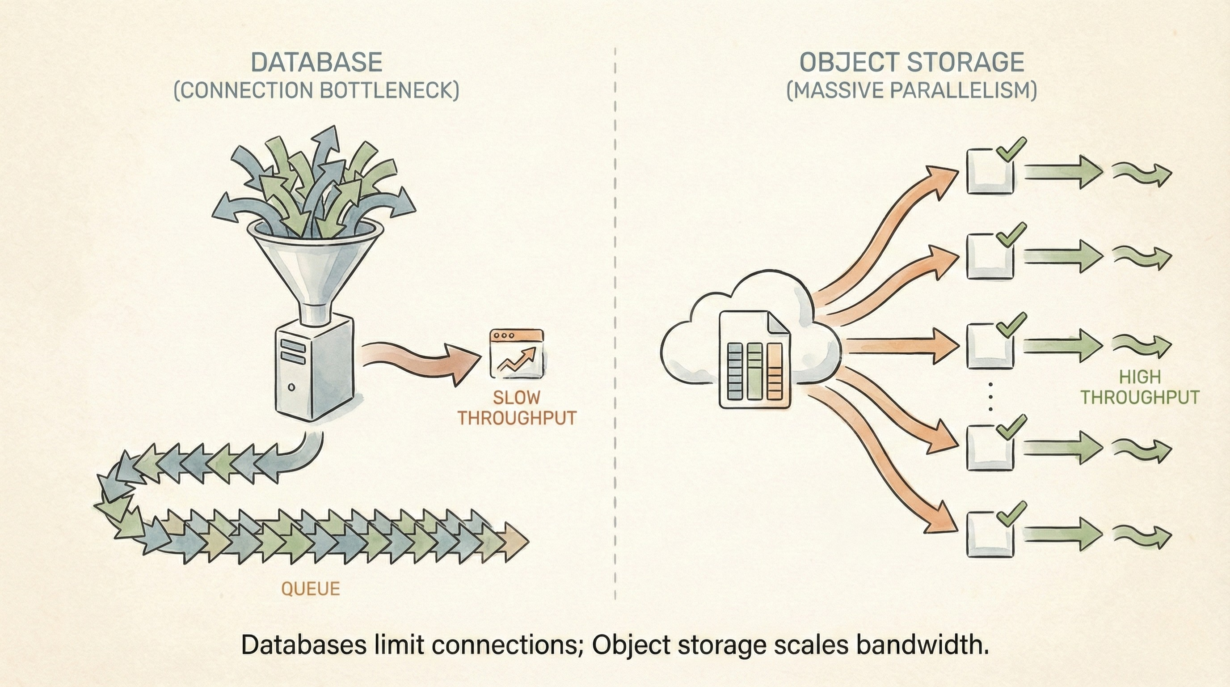
Traditional databases are stateful bottlenecks. A PostGIS server runs on a machine with finite CPU, memory, and connection slots. Scale by adding cores (vertical). You hit a ceiling—one machine can only get so big. Users queue for connections. Throughput plateaus.
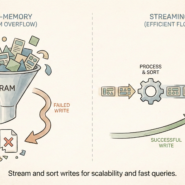
Parquet on object storage is shared-nothing. No running server. No connection limits. A file sits in S3. A thousand workers read it simultaneously, each pulling different row groups. No coordination needed. Each worker gets independent throughput to the object store. Aggregate bandwidth often exceeds what a single database SSD can provide.
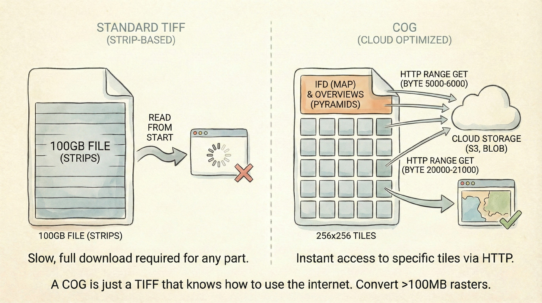
The magic is splittability. A 100GB Parquet file divides into 100 row groups. Spark assigns groups to 100 different machines. They read in parallel without stepping on each other. Try this with a database—connection pooling becomes the bottleneck.
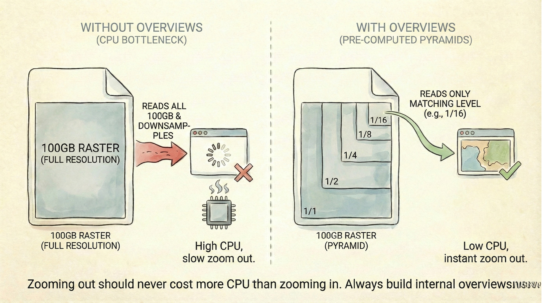
This changes everything for analytics. Training machine learning models? Parquet feeds data to 50 workers faster than a database can serialize responses. Global-scale raster processing? Each worker reads its region from S3 simultaneously.
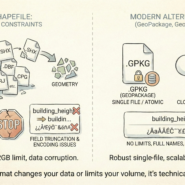
The tradeoff: Parquet is read-optimized. Multiple concurrent writes aren’t transactional. Editing shared features requires a database with locks and ACID guarantees. Use Parquet for analytics and batch processing. Use databases for coordinated editing.
The rule: Databases have connection limits. Object storage has throughput limits. For scale, choose the latter. Parquet isn’t faster than PostGIS—it’s parallelizable.